What’s New in High Availability
In
general, a couple of Microsoft SQL Server 2008 configuration options
offer a very strong database engine foundation that can be highly
available (7 days a week, 365 days a year). Microsoft’s sights are set
on being able to achieve five-nines reliability with almost everything
it builds. An internal breakthrough introduced with SQL Server 2005
called “copy-on-write” technology, has enabled Microsoft to greatly
enhance several of its database high availability options.
Here are a few of the most
significant enhancements and new features that have direct or indirect
effects on increasing high availability for a SQL Server 2008–based
implementation:
Increased number of nodes in a SQL cluster— You can create a SQL cluster of up to 64 nodes on Windows Server Data Center 2008.
Enhancements to do unattended cluster setup—
Instead of having to use wizards to set up SQL clustering, you can use
the Unattended Cluster Setup mode. This is very useful for fast
re-creation or remote creation of SQL clustering configurations.
All SQL Server 2008 services as cluster managed resources— All SQL Server 2008 services are now cluster aware.
SQL Server 2008 database mirroring— Database mirroring creates an automatic failover capability to a “hot” standby server.
SQL Server 2008 peer-to-peer replication— This option of data replication uses a publisher-to-publisher model (hence peer-to-peer).
SQL Server 2008 automatic corruption recovery from mirror— This enhancement in database mirroring recognizes and corrects corrupt pages during mirroring.
SQL Server 2008 mirroring transaction record compression—
This feature allows for compression of the transaction log records used
in database mirroring to increase the speed of transmission to the
mirror.
SQL Server 2008 fast recovery—
Administrators can reconnect to a recovering database after the
transaction log has been rolled forward (and before the rollback
processing has finished).
Online restore— Database administrators can perform a restore operation while the database is still online.
Online indexing—
The online index option allows concurrent modifications (updates,
deletes, and inserts) to the underlying table or clustered index data
and any associated indexes during index creation time.
Database snapshot—
SQL Server 2008 allows for the generation and use of a read-only,
stable view of a database. The database snapshot is created without the
overhead of creating a complete copy of the database or having
completely redundant storage.
Hot additions— This feature allows for hot additions to memory and CPU.
Addition of a snapshot isolation level—
A new snapshot isolation (SI) level is being provided at the database
level. With SI, users can access the last committed row, using a
transactionally consistent view of the database.
Dedicated administrator connection—
SQL Server 2008 supports a dedicated administrator connection that
administrators can use to access a running server even if the server is
locked or otherwise unavailable. This capability enables administrators
to troubleshoot problems on a server by executing diagnostic functions
or Transact-SQL statements without having to take down the server.
At the operating system (OS)
level, Virtual Server 2005 has firmly established virtualization for
both development and production environments and allows entire
application and database stacks to run on a completely virtual operating
system footprint that will never bring down the physical server.
Note
Microsoft has announced
that log shipping will be deprecated soon. Although it has been
functionally replaced with database mirroring, log shipping remains
available in SQL Server 2008. However, you should plan to move off log
shipping as soon as you can.
Keep in mind that
Microsoft already has an extensive capability in support of high
availability. The new HA features add significant gains to the already
feature-rich offering.
What Is High Availability?
The availability continuum depicted in Figure 1
shows a general classification of availability based on the amount of
downtime an application can tolerate without impacting the business. You
would write your service-level agreements (SLAs) to support and try to
achieve one of these continuum categories.
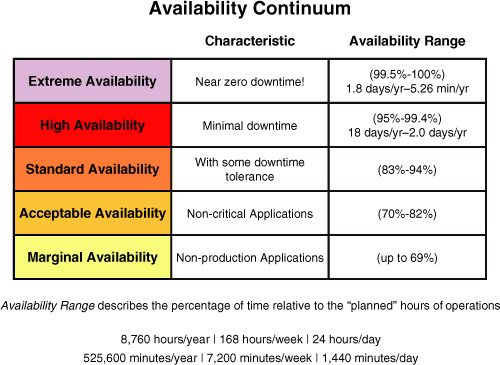
Topping the chart is the
category extreme availability, so named to indicate that this is the
least tolerant category and is essentially a zero (or near zero)
downtime requirement (that is, sustained 99.5% to 100% availability).
The mythical five-nines falls at the high end of this category. Next is
the high availability category, which has a minimal tolerance for
downtime (that is, sustained 95% to 99.4% availability). Most “critical”
applications would fit into this category of availability need. Then
comes the standard availability category, with a more normal type of
operation (that is, sustained 83% to 94% availability). The acceptable
availability category is for applications that are deemed noncritical to
a company’s business, such as online employee benefit package
self-service applications. These applications can tolerate much lower
availability ranges (sustained 70% to 82% availability) than the more
critical services. Finally, the marginal availability category is for
nonproduction custom applications, such as marketing mailing label
applications that can tolerate significant downtime (that is, sustained
0% to 69% availability). Again, remember that availability is measured
by the planned operation times of the application.
Achieving the
mythical five-nines (that is, a sustained 99.999% availability) falls
into the extreme availability category (which tolerates between 5.26
minutes and 1.8 days of down time per year). In general, the computer
industry calls this high availability, but we push this type of
near-zero downtime requirement into its own extreme category, all by
itself. Most applications can only dream about this level of
availability because of the costs involved, the high level of
operational support required, the specialized hardware that must be in
place, and many other extreme factors.The Fundamentals of HA
Every minute of downtime
you have today translates into losses that you cannot well afford. You
must fully understand how the hardware and software components work
together and how, if one component fails, the others will be affected.
High availability of an
application is a function of all the components together, not just one
by itself. Therefore, the best approach for moving into supporting high
availability is to work on shoring up the basic foundation components of
hardware, backup/recovery, operating system upgrading, ample vendor
agreements, sufficient training, extensive quality assurance/testing,
rigorous standards and procedures, and some overall risk-mitigating
strategies, such as spreading out critical applications over multiple
servers. By addressing these first, you add a significant amount of
stability and high-availability capability across your hardware/system
stack. In other words, you are moving up to a necessary level before you
completely jump into a particular high-availability solution. If you do
nothing further from this point, you have already achieved a portion of
your high-availability goals.
Hardware Factors
You need to start by
addressing your basic hardware issues for high availability and fault
tolerance. This includes redundant power supplies, UPS systems,
redundant network connections, and ECC memory (error correcting). Also
available are “hot-swappable” components, such as disks, CPUs, and
memory. In addition, most servers are now using multiple CPUs,
fault-tolerant disk systems such as RAID, mirrored disks, storage area
networks (SANs), Network Attached Storage (NAS), redundant fans, and so
on.
Cost may drive the full extent of what you choose to build out. However, you should start with the following:
Redundant power supplies (and UPSs)
Redundant fan systems
Fault-tolerant disks, such as RAID (1 through 10), preferably “hot swappable”
ECC memory
Redundant Ethernet connections
Backup Considerations
After you consider hardware,
you need to look at the basic techniques and frequency of your disk
backups and database backups. For many companies, the backup plan isn’t
what it needs to be to guarantee recoverability and even the basic level
of high availability. At many sites, database backups are not being
run, are corrupted, or aren’t even considered necessary. You would be
shocked by the list of Fortune 1000 companies where this occurs.
Operating System Upgrades
You need to make sure that
all upgrades to your OS are applied and also that the configuration of
all options is correct. This includes making sure you have antivirus
software installed (if applicable), along with the appropriate firewalls
for external-facing systems.
Vendor Agreements Followed
Vendor
agreements come in the form of software licenses, software support
agreements, hardware service agreements, and both hardware and software
service-level agreements. Essentially, you are trying to make sure you
can get all software upgrades and patches for your OS and for your
application software at any time, as well as get software support,
hardware support agreements, and both software and hardware SLAs in
place to guarantee a level of service within a defined period of time.
Training Kept Up to Date
Training is multifaceted in
that it can be for software developers to guarantee that the code they
write is optimal, for system administrators who need to administer
applications, and even for end users themselves to make sure they use
the system correctly. All these types of training play into the ultimate
goal of achieving high availability.
Quality Assurance Done Well
Testing as much as possible—and
doing it in a very formal way—is a great way to guarantee a system’s
availability. Dozens of studies over the years have clearly shown that
the more thoroughly you test (and the more formal your QA procedures),
the fewer software problems you will have. Many companies foolishly
skimp on testing, which has a huge impact on system reliability and
availability.
Standards/Procedures Followed
Standards and procedures
are interlaced tightly with training and QA. Coding standards, code
walkthroughs, naming standards, formal system development life cycles,
protection of tables from being dropped, use of governors, and so on all
contribute to more stable and potentially more highly available
systems.
Server Instance Isolation
By design, you may want to
isolate applications (such as SQL Server’s applications and their
databases) away from each other to mitigate the risk of such an
application causing another to fail.
Plain and simple, you
should never put applications in each other’s way if you don’t have to.
The only things that might force you to load up a single server with all
your applications would be expensive licensing costs for each server’s
software and perhaps hardware scarcity (strict limitations to the number
of servers available for all applications). A classic example occurs
when a company loads up a single SQL Server instance with between two
and eight applications and their associated databases. The problem is
that the applications are sharing memory, CPUs, and internal work areas,
such as tempdb. Figure 2 shows an overloaded SQL Server instance that is being asked to service seven major applications (Appl 1 DB through Appl 7 DB).
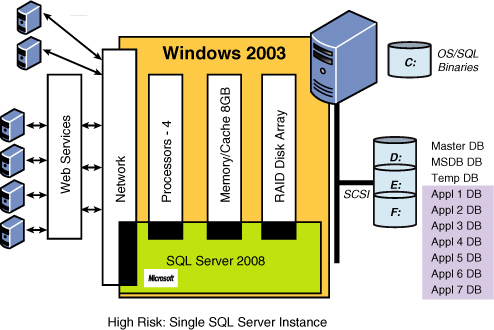
The single SQL Server instance in Figure 2 is sharing memory (cache) and critical internal working areas, such as tempdb,
with all seven major applications. Everything runs fine until one of
these applications submits a runaway query, and all other applications
being serviced by that SQL Server instance come to a grinding halt. Most
of this built-in risk could be avoided by simply putting each
application (or perhaps two applications) onto their own SQL Server
instance, as shown in Figure 3. This fundamental design approach greatly reduces the risk of one application affecting another.
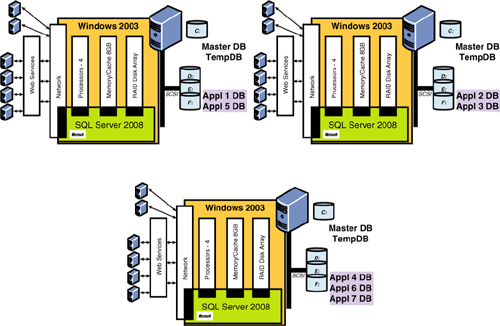
Many
companies make this fundamental error. The trouble is that they keep
adding new applications to their existing server instance without a full
understanding of the shared resources that underpin the environment. It
is often too late when they finally realize that they are hurting
themselves “by design.” You have now been given proper warning of the
risks. If other factors, such as cost or hardware availability, dictate
otherwise, then at least it is a calculated risk that is entered into
knowingly (and is properly documented as well).